
Коротко: предиктивный ТОиР, цифровые двойники и интеграция с EAM/ERP уже не обсуждаются как «когда-нибудь». Под них выделены бюджеты, объявлены тендеры. Но начинать приходится с данных, которые накапливались десятилетиями без единого стандарта. В статье — методология подготовки инженерного архива действующего объекта: три этапа «извлечение — нормализация — связывание».
Проблема, которую не замечают до старта проекта
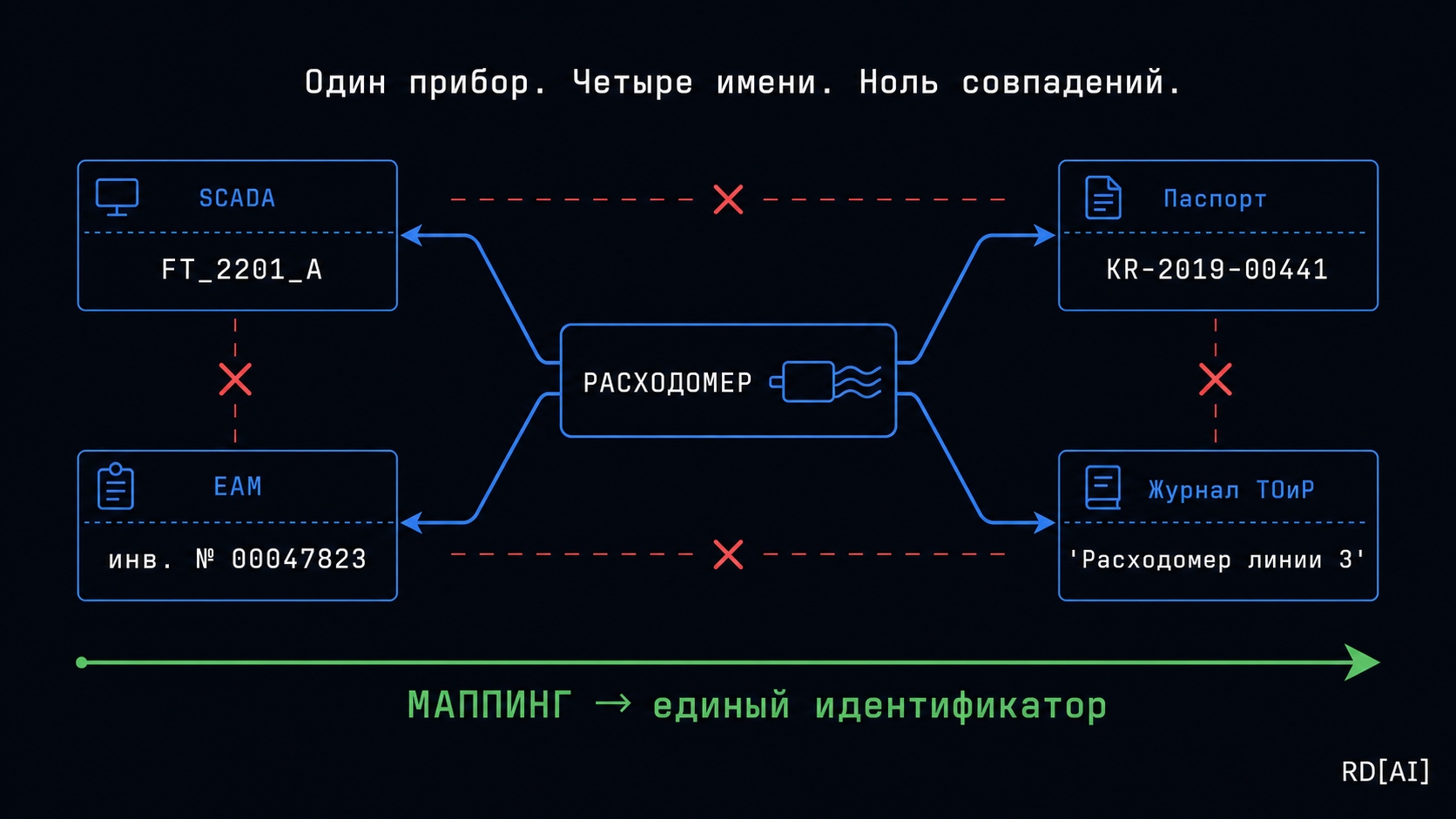
Датчик давления на линии подачи сырья. В проекте — «PT-2214». В конфиге PLC — «AI_CH07_RACK3». В паспорте на прибор — серийный номер завода-изготовителя. В заявке на поверку — инвентарный номер предприятия.
Четыре источника. Один прибор. Ни одного совпадения.

Предиктивная модель обучена на тегах SCADA — и не знает, что PT-2214 и AI_CH07_RACK3 это одно и то же устройство. Когда приходит сигнал о деградации — система не может соотнести его с историей обслуживания, потому что в журнале ТОиР прибор записан под инвентарным номером из бухгалтерии. Предупреждение либо теряется, либо уходит не тому.
Это не редкий случай. Это типичное состояние данных на объектах, которые строились в 1980–2000-е годы без системы управления инженерными данными (СУИД). Таких объектов в России большинство.
Почему так произошло
Объект строился поэтапно, разными подрядчиками, в разные эпохи. Каждый подрядчик по АСУ ТП реализовывал конфигурацию «как умел» — со своей системой именования тегов. Проектировщик работал в одной САПР, КИПовщик — в другой, эксплуатационщики вели журналы в Excel или вовсе на бумаге. Системы закупок и бухгалтерии пришли позже и создали ещё один слой идентификаторов.
В результате сложилась структура, которую сложно назвать «данными» в инженерном смысле. Это накопленные записи о событиях и объектах, разбросанные по десяткам несвязанных источников: бэкапы SCADA, конфиги PLC, отсканированные паспорта, исполнительная документация в бумажном виде, выгрузки из систем ТОиР разных поколений.
Установки функционируют не одно десятилетие и неоднократно подвергались реконструкции и ремонту. Стандартный подход — строить модель от стадии проектирования — тут не работает. Единственным источником гарантированно актуальной информации является сама установка. Александр Тучков, Бюро ESG — об опыте создания информационных моделей 38 нефтеперерабатывающих установок[1]
Что происходит, когда данные не готовы
Сегодня нефтегазовые и нефтехимические компании активно инвестируют в три направления: предиктивный ТОиР на основе ИИ, интеграцию с EAM/ERP-системами и цифровые двойники активов. Во всех трёх случаях качество результата напрямую зависит от качества исходных данных об оборудовании.
- Предиктивный ТОиР. ИИ-модель обучается на исторических данных о поведении оборудования. Если теги в SCADA не соотнесены с позициями в журнале ТОиР и паспортами на приборы — модель не может построить корректную историю объекта. Предсказание либо невозможно, либо недостоверно.
- Интеграция с EAM/ERP. Основная ценность EAM — планирование ремонтов и управление запасами на основе актуальных данных об оборудовании. Если в систему загружена номенклатура из бухгалтерии, а не инженерные теги, плановики работают со списком инвентарных номеров, не понимая, какое именно оборудование стоит на объекте.
- Цифровой двойник. Цифровой двойник строится точным отражением физического объекта. Если исходная документация не актуализирована после реконструкций — двойник воспроизводит устаревшую схему.
Legacy-данные разрознены, неструктурированы — на их оцифровку потребуются значительные усилия и средства. Вероника Панайотова, Сибур Диджитал — о задачах СУИД в нефтехимии[2]
Методология: три этапа подготовки данных
Работа с инженерным архивом действующего объекта требует воспроизводимой методологии. Импровизация на каждом объекте не масштабируется и не даёт гарантированного результата. На практике задача решается в три этапа.
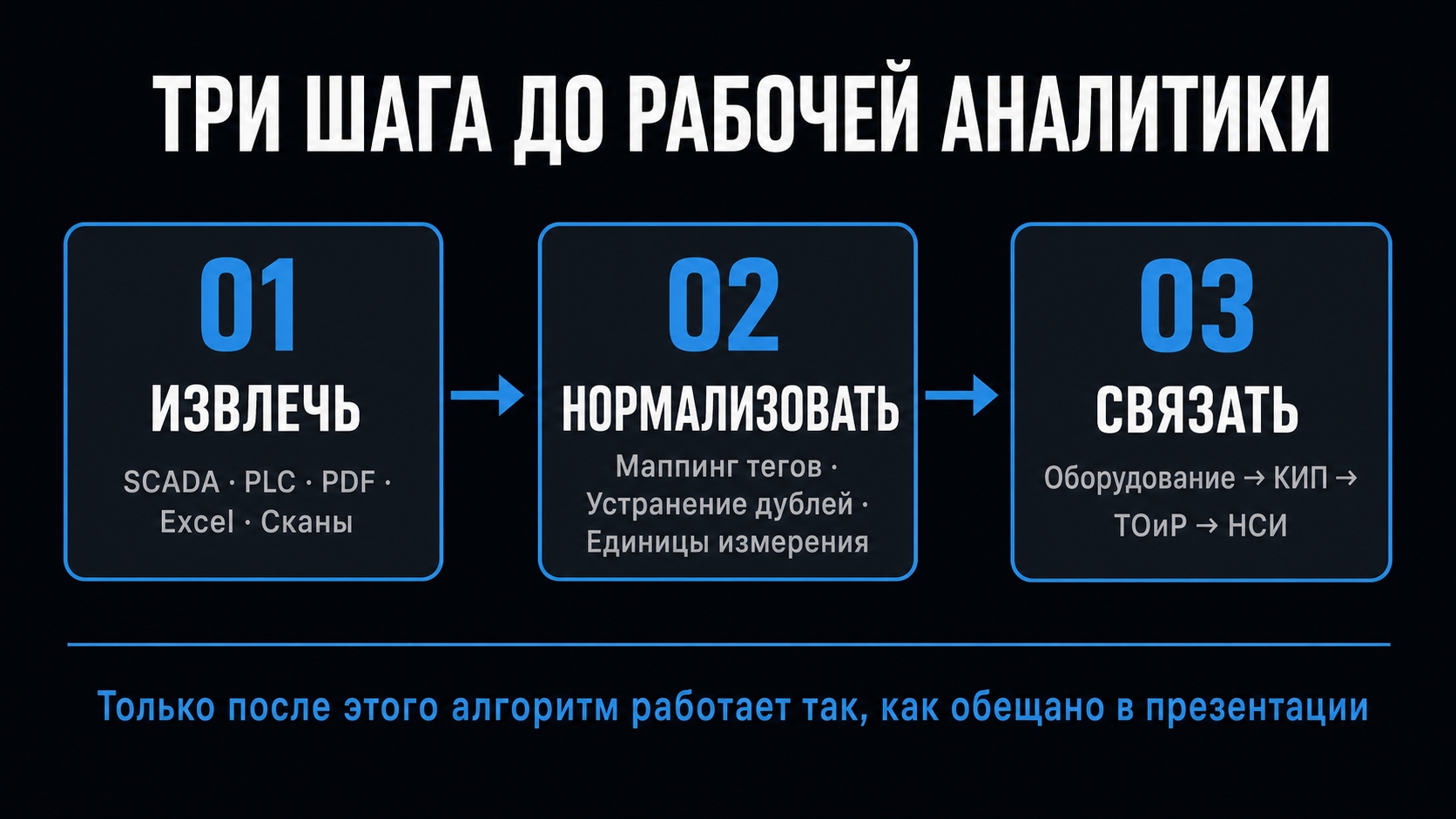
Этап 1. Извлечение
Инвентаризация всех источников данных на объекте: бэкапы и выгрузки SCADA, конфигурационные файлы PLC, исполнительная и эксплуатационная документация (от структурированных XML до сканов), паспорта оборудования, базы данных ТОиР и ТОРО, спецификации из проектной документации.
На этом этапе критически важна трассируемость: каждое извлечённое значение должно знать свой источник — файл, страницу или строку. Данные без источника не могут считаться верифицированными.
Этап 2. Нормализация
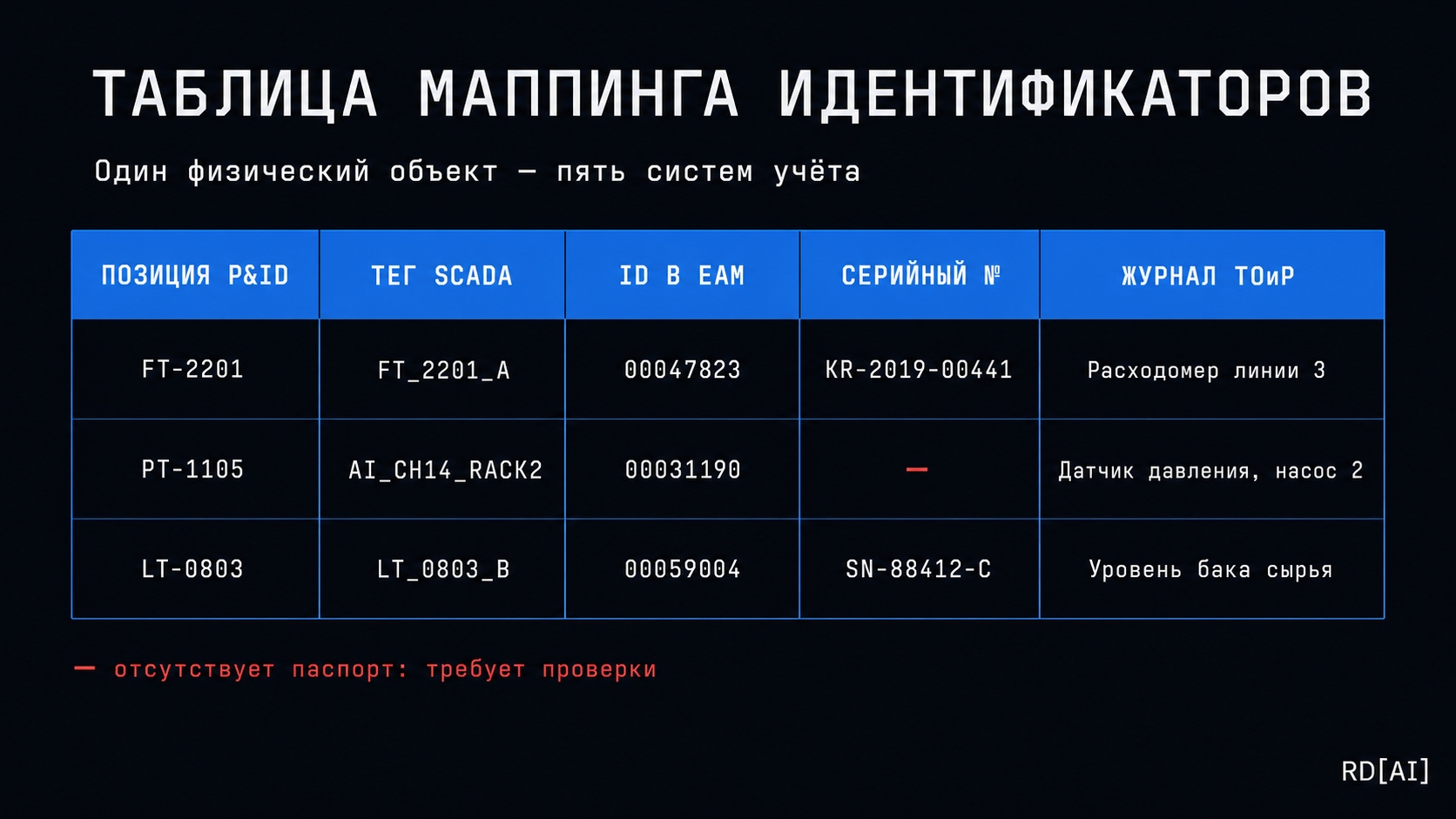
Приведение разнородных данных к единой структуре. Центральная задача — построение маппинга идентификаторов: установить, что PT-2214 в проекте, AI_CH07_RACK3 в конфиге PLC и инвентарный номер в EAM — это один и тот же физический прибор.
Нормализация включает: устранение дублей, разрешение конфликтов (когда два источника дают разные значения для одного объекта — оба фиксируются с пометкой о конфликте и передаются на верификацию специалисту), стандартизацию единиц измерения и форматов.
Этап 3. Связывание
Построение иерархии объектов и связей между ними: оборудование — КИП — документация — история обслуживания — НСИ. Результат — единая инженерная база, где каждый объект имеет однозначный идентификатор, набор атрибутов и прослеживаемые связи с другими объектами и документами.
Именно в таком виде данные становятся пригодными для загрузки в СУИД, EAM, предиктивные модели и цифровые двойники.
Три типичные постановки задачи
На практике подготовка инженерного архива встречается в трёх рабочих сценариях.
Подготовка к предиктивному ТОиР
Задача: создать единый справочник оборудования с историей обслуживания, привязанной к тегам SCADA. На входе: конфиги PLC, архивы SCADA, журналы ТОиР в Excel. На выходе: нормализованная база тегов с маппингом на позиции из журналов и паспортов — готовая к загрузке в ИИ-систему или EAM.
Интеграция с EAM
Задача: обогатить EAM-систему инженерными данными вместо бухгалтерской номенклатуры. На входе: инвентарные карточки из ERP, исполнительная документация, паспорта. На выходе: структурированная номенклатура оборудования с техническими характеристиками, привязанная к функциональным позициям на схемах.
Цифровой двойник
Задача: подготовить данные об оборудовании в состоянии «как эксплуатируется» для наполнения 3D-модели или информационной модели объекта. Александр Шишкин из Газпром нефти, описывая управление информационным стандартом на действующих компрессорных станциях, фиксирует ту же точку входа: стандарт невозможно ввести без предварительной инвентаризации того, что уже есть на объекте[3].
Тема активно обсуждается в отрасли
Три независимых направления экспертизы сходятся к одной проблеме. Александр Тучков (Бюро ESG) системно разрабатывает методологию создания эксплуатационных моделей brownfield-объектов — с позиции 3D-моделирования и работы с P&ID. Александр Шишкин (Газпром нефть) описывает задачу управления информационным стандартом на действующих КС — то есть то, что происходит после того, как данные приведены в порядок. Вероника Панайотова (Сибур Диджитал) строит СУИД для новых объектов и прямо указывает на нерешённость задачи для legacy-активов.
Между этими тремя позициями — методологический пробел: как именно работать с унаследованными данными АСУ ТП и архивами, которые накопились до появления СУИД. Именно этот пробел закрывает описанная выше методология.
Тендеры на СУИД не находят исполнителей не потому, что нет бюджетов или подрядчиков. А потому что заказчик в ТЗ описывает целевую систему, а исполнитель видит, что начинать нужно с инвентаризации десятков legacy-источников. Это разные проекты, разная экономика, разная ответственность. Подготовка данных — отдельная фаза, и её нужно отделить от внедрения системы.
Полная версия материала с подробными ссылками опубликована на профильном портале isicad.ru.
Готовите архив под СУИД, EAM или предиктивный ТОиР?
Экспресс-аудит инженерного архива за 5 рабочих дней. На выходе — оценка пригодности данных, дельта-список пробелов и план следующей фазы. Фиксированная цена 150 000 ₽, без vendor lock-in.
Подробнее об услуге — на странице подготовка инженерных архивов. Скачать КП «Экспресс-аудит инженерного архива» (PDF).
FAQ
Почему тендеры на СУИД часто не находят исполнителей?
Заказчик описывает в ТЗ целевую систему (СУИД, EAM, цифровой двойник), а исполнитель видит, что начинать придётся не с системы, а с разбора десятков legacy-источников: SCADA, PLC, паспортов, сканов, журналов ТОиР. Это другой объём работ, другой бюджет и другая ответственность. Подрядчики либо отказываются, либо завышают сметы в полтора-два раза, и закупка завершается без контракта.
Что такое маппинг идентификаторов?
Маппинг — установление того, что PT-2214 в проекте, AI_CH07_RACK3 в конфиге PLC, инвентарный номер в EAM и серийный в паспорте — это один и тот же физический прибор. Без маппинга ИИ-модель «не знает», что разные имена относятся к одному объекту: история обслуживания не привязывается к сигналу, предсказания не работают.
Можно ли запустить предиктивный ТОиР без подготовки архива?
Технически можно. На практике модель не сможет соотнести сигнал из SCADA с историей обслуживания из журнала ТОиР, потому что прибор записан под разными идентификаторами. Предупреждение либо теряется, либо уходит не тому. Поэтому крупные проекты в нефтехимии и нефтегазе начинают с инвентаризации, а не с моделей.
Сколько времени занимает экспресс-аудит инженерного архива?
5 рабочих дней. На выходе — оценка пригодности данных к автоматизации, дельта-список пробелов и план следующей фазы. Стоимость 150 000 ₽, фиксированная. Без vendor lock-in: все артефакты передаются в открытых форматах.
- Тучков А. Принципы разработки импортозамещающих САПР PlantLinker и управление инженерными данными. isicad.ru
- Панайотова В. «Я теряю миллион каждый час, поэтому купил программу за…» Habr, СИБУР официальный блог
- Шишкин А. Управление информационным стандартом на объектах Газпром нефти. dprom.online
Об авторе. Руслан Гельманов — основатель и директор RD[AI], к.п.н. (РЭА им. Г.В. Плеханова). Более 15 лет в операционном и коммерческом управлении в международных компаниях — DHL Express, DB Schenker, Discovery Networks, Iron Mountain. Опыт в отраслях с высокими требованиями к процессам и данным: клинические исследования, деловая авиация, обработка и защита корпоративных данных.
Комментарии
Комментарии проходят модерацию и появляются на странице после подтверждения.
Загружаем комментарии...